
Let's be honest. For a long time, Postman was the main tool for anyone working with APIs. If you've dealt with APIs, you've probably used Postman a lot – making collections, setting up environments, and hitting that "Send" button. It was the top choice and made dealing with APIs much easier for everyone. Big thanks to Postman for that!
But lately, does Postman feel a bit… much? It seems like it’s gotten bigger and, strangely, slower. What used to be a quick tool for simple API calls now feels like a giant program.
What’s Up with Postman? Why People Are Searching for Alternatives to Postman
It’s not just you. Developers everywhere – on forums, in team chats, and on dev.to – are talking about the same issues. If these sound familiar, you're on the same page as many others:
- It Feels Slow and Heavy: Remember when Postman was fast? For lots of us, it doesn’t feel that way anymore. Starting it up can take a while, and if you have a lot of API requests saved, it can really drag. Many people agree it uses up too much computer power.
- Too Many Features? Postman does a lot now. Lots of features can be good, but it also means the app can look crowded. It can be harder to learn, especially if you just want to do simple API tests. Sometimes you just want to send a quick request, not learn a whole new system.
- Paying for More: This is a big one. Some things that used to be free in Postman, like the local "Scratch Pad" for quick tests without saving online, are gone or now cost money. Working together with your team, which is super important, also means you’ll likely have to pay. For single developers, small companies, or teams trying to save money, Postman might not seem like the best deal anymore.
- All About the Cloud (and Being Tied Down): Postman really wants you to use their cloud services for everything. This means you usually have to log in, and your data is stored online. Some developers worry about keeping their data private or want tools that work well offline. Plus, many don’t like feeling locked into one company's way of doing things.
It’s a common story: a popular tool gets bigger and adds more stuff, but in the process, it stops being the best fit for many of the people who first loved it. People aren't always looking for a tool that does more than Postman. Often, they want something that does the main job – API testing and development – but is faster, easier, more open (like open-source), or doesn't cost as much.
So, if you're feeling this way and wondering if there's a better, simpler, or just different tool for your API tasks, you're looking in the right place. The good news? There are now many great alternatives out there. Lots of new, smart tools are ready to help you out.
Let's check out some of the best ones that could change how you work with APIs...
1. Bruno: A Git-Friendly, Local-First Postman Alternative

Bruno is a newer, highly promising Postman alternative that is rapidly gaining traction due to its unique philosophy: API collections are stored directly on your filesystem using a plain text markup language called Bru Lang. This makes it inherently Git-friendly.
Key Strengths:
-
Local-First & Git Native: Collections are folders of plain text
.brufiles. Version control your API tests alongside your code using Git, with meaningful diffs.
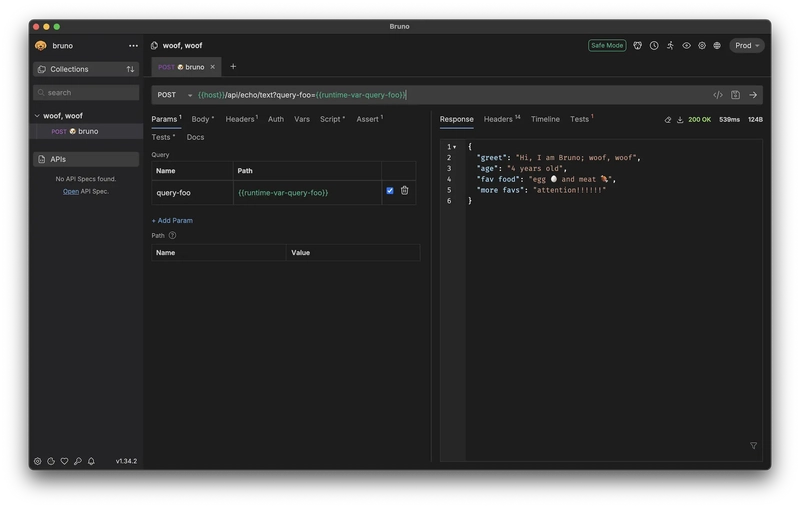
- Bru Lang: A simple, human-readable markup language for defining API requests, assertions, and scripts.

- Scripting with JavaScript: Supports scripting for pre-request and post-response actions.

- CLI Runner (Bruno CLI): Execute collections from the command line, enabling CI/CD integration.
- Clean & Fast UI: A lightweight and responsive graphical interface.
- Platforms: Windows, macOS, Linux
- Pricing: Open Source (actively seeking funding via GitHub Sponsors, with a future "Golden Edition" planned for optional paid features).

- Things to Consider: Being newer, its feature set, while growing rapidly, might not yet match the sheer breadth of Postman in every niche area. The ecosystem of integrations is still developing.
2. Apidog: An All-in-One Collaborative Postman Alternative

Apidog positions itself as an integrated collaboration platform for the entire API lifecycle: design, development, debugging, automated testing, and mocking, all within a single application.
Key Strengths:
- Integrated API Lifecycle Management: Combines API design (visual editor, OpenAPI/Swagger import/export), documentation generation, debugging, automated testing (with scenarios and data-driven testing), and advanced mocking in one tool.

- Strong Team Collaboration Features: Real-time sync, role-based access control, project management for API development.
- Intelligent Mocking: Advanced mock features, including expectation-based and dynamic mocks.
- CI/CD Integration: Supports integration with popular CI/CD tools.

- Attractive UI: Modern and generally well-received user interface.

- Platforms: Windows, macOS, Linux, Web
- Pricing: Generous free tier for individuals and small teams. Paid plans ("Team," "Enterprise") for larger teams, advanced features, and higher usage limits.

- Things to Consider: As an all-in-one tool, it offers a wide range of features that go beyond simple request sending—ideal for users who want to scale their API workflows over time. Its active development means it's continuously improving, especially in areas like advanced test automations.
3. Hoppscotch: The Web-Based Open-Source Postman Alternative

Formerly known as Postwoman, Hoppscotch burst onto the scene as a "free, fast, beautiful" API request builder that runs directly in your browser. It's remarkably lightweight and offers a slick, modern UI that appeals to many.
Key Strengths:
- Blazing Fast & Web-Based: No installation needed for basic use; access it from any browser.
- Progressive Web App (PWA): Can be "installed" as a PWA for a more native-app feel.
- Real-time Protocol Support: Excellent support for WebSockets, Socket.IO, MQTT, and SSE alongside REST and GraphQL.

- GraphQL Explorer: Intuitive interface for exploring GraphQL schemas.
- Team Collaboration (Cloud): Offers cloud-based team workspaces, collections, and history sync.

Cloud Pricing:

Self-Host Pricing:

- Platforms: Web, PWA (Windows, macOS, Linux, Mobile)
- Pricing: Open Source (self-hostable). Free Cloud Tier. Paid Cloud Tiers for enhanced team features and limits.
Cloud Pricing:
Self-Host Pricing:
- Things to Consider: Being primarily web-based, offline functionality (though present via PWA) might not be as robust as dedicated desktop apps for all scenarios. Advanced enterprise features might still be maturing compared to established players.
4. Insomnia: A Sleek and Powerful Open-Source Postman Alternative

Insomnia, now under the Kong umbrella, consistently ranks as a top Postman alternative. It's a cross-platform desktop application celebrated for its beautiful, minimalist interface, responsive performance, and robust feature set that rivals Postman in many core areas.
Key Strengths:
- Elegant UI/UX: Clean, uncluttered, and highly intuitive, making it a pleasure to use.
- OpenAPI Design & Testing: Strong support for designing, debugging, and testing against OpenAPI (Swagger) specifications. Includes linting and a visual editor.
- GraphQL Champion: Excellent, first-class support for GraphQL, including schema introspection, autocompletion, and explorer.
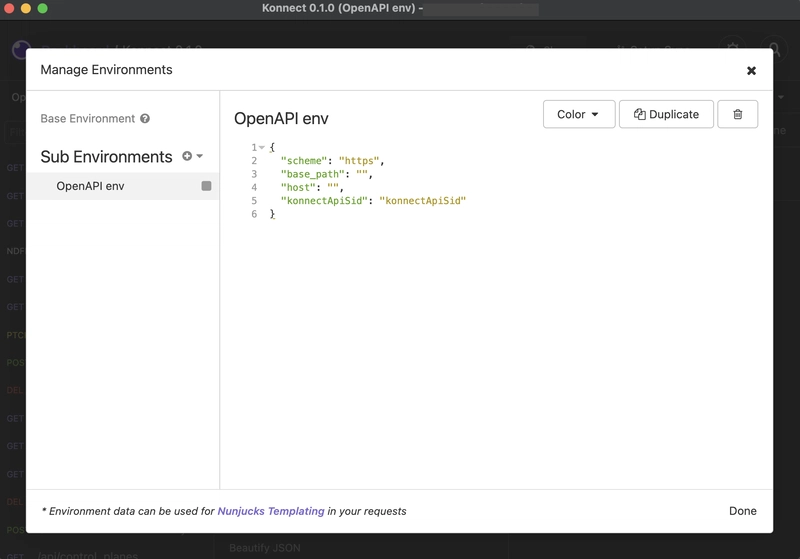
- Environment & Sub-Environment Variables: Powerful templating and environment management.
- Code Snippet Generation: Generate client code in various languages.

- Platforms: Windows, macOS, Linux
- Pricing: Free (core features are very generous), Paid (Insomnia Plus/Ultimate for team sync, E2E encryption, enterprise features).

- Things to Consider: While the core is open source, team sync and some advanced features are part of the paid offering by Kong. Some users have noted increased resource usage in very recent versions, though generally still lighter than Postman.
5. cURL: The Veteran Command-Line Postman Alternative

No list of Postman alternatives, especially those touching the CLI, is complete without mentioning cURL (Client URL). It's the ubiquitous, battle-tested command-line tool for transferring data with URLs, supporting a vast array of protocols.
Key Strengths:
- Universally Available: Pre-installed on most Linux and macOS systems, easily available for Windows.

- Protocol King: Supports DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, MQTT, POP3, POP3S, RTMP, RTMPS, RTSP, SCP, SFTP, SMB, SMBS, SMTP, SMTPS, TELNET, TFTP, WS, WSS.
- Highly Scriptable: The backbone of countless automation scripts and system tasks.
- Incredibly Robust & Powerful: Offers fine-grained control over every aspect of a request.
- Platforms: Virtually everywhere.
- Pricing: Free, Open Source.
- Things to Consider: Syntax can be verbose and less intuitive for beginners compared to HTTPie. Managing complex JSON bodies or authentication flows can be cumbersome without helper scripts or tools. Lacks a GUI for collection management or response visualization.
6. VS Code REST Client (Huachao Mao): An IDE-Integrated Postman Alternative

For developers living in Visual Studio Code, this popular extension offers a seamless way to send HTTP requests and view responses directly within the editor. Requests are defined in plain text .http or .rest files, which promotes an "API-as-code" approach.
Key Strengths:
- Deep VS Code Integration: Leverages the editor's features (syntax highlighting, source control).

ng image](...)
-
Plain Text Requests: Define requests in simple
.httpfiles, easily versioned with Git.
- Multiple Requests per File: Organize related requests in a single file.
-
Variables & Environments: Supports environment variables (from a
settings.jsonor dedicated environment files). - GraphQL Support: Can send GraphQL queries.
- Code Snippet Generation: Generate cURL commands or code for various languages.
- Response History & Saving: View history and save response bodies to files.

- Platforms: VS Code (Windows, macOS, Linux)
- Pricing: Free, Open Source.
- Things to Consider: Lacks the sophisticated GUI for collection management or advanced test suite organization found in dedicated tools. Collaboration features rely on sharing Git repositories.
7. JetBrains HTTP Client: Another Excellent IDE-Based Postman Alternative

Built directly into IntelliJ IDEA Ultimate, WebStorm, PyCharm Professional, GoLand, PhpStorm, Rider, and other paid JetBrains IDEs, this HTTP client also uses .http request files. It offers a polished graphical interface for requests and responses right within the IDE.
Key Strengths:
- Seamless JetBrains IDE Integration: Feels like a natural part of the IDE.
- Rich UI for Requests/Responses: Excellent inline rendering of responses (JSON, HTML, images), comparison tools.

- .http File Format: Similar to the VS Code REST Client, requests are stored in text files.
- Environment Variables & Scripting: Supports environment variables and JavaScript for pre-request/response handling.
- GraphQL, gRPC, WebSocket Support: Comprehensive protocol coverage.

- Platforms: JetBrains IDEs (Windows, macOS, Linux)
- Pricing: Included with paid JetBrains IDEs. Some free IDEs like IntelliJ IDEA Community Edition might have a more basic version or require a plugin.
- Things to Consider: Tied to the JetBrains ecosystem. While powerful, it might be overkill if you're not already using a JetBrains IDE.
8. Restfox: A Minimalist Offline-First Postman Alternative

Restfox champions simplicity and speed. It's an offline-first HTTP client designed to be a fast, no-frills alternative for developers who find tools like Postman or Insomnia too bloated or slow for quick API interactions.
Key Strengths:
- Extremely Lightweight & Fast: Noticeably quick startup and operation.
- Offline-First Design: Works entirely offline, no cloud account needed.
- Cross-Platform: Available as desktop apps and a web version.
- Core Features Covered: Workspaces, collections, environments, HTTP/HTTPS, basic scripting (JavaScript).
- Platforms: Windows, macOS, Linux, Web
- Pricing: Open Source.
- Things to Consider: Feature set is intentionally limited compared to Postman or Insomnia. Not suitable for complex test automation or extensive team collaboration requiring cloud features.
9. Thunder Client: A VS Code GUI Postman Alternative

Another strong contender for VS Code users, Thunder Client provides a more GUI-centric experience for API testing, closely resembling Postman's core interface but living directly within the editor.
Key Strengths:
- Lightweight & Fast: Offers a good balance of features and performance within VS Code.
- Postman-like UI: Familiar interface for those transitioning from Postman.
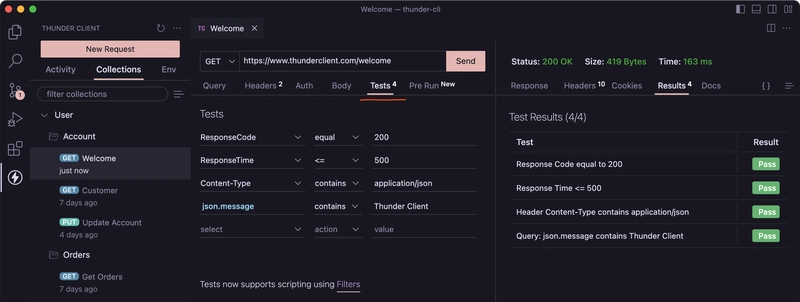
- Collections & Environment Variables: Standard features for organizing requests and managing configurations.
- Basic Testing Capabilities: Supports simple assertions.
- Git Integration: Collection data is stored in JSON files, easily versionable with Git.
- Platforms: VS Code (Windows, macOS, Linux)
- Pricing: Free core version. Paid "Pro" and "Business" plans for features like cloud sync, team collaboration, and more advanced testing.

- Things to Consider: While it mimics Postman's UI, the depth of advanced features (e.g., complex scripting, mock servers, monitoring) might not be as extensive, especially in the free tier.
10. Paw (for Mac): A Premium Native macOS Postman Alternative

Paw is a Mac-exclusive, beautifully designed, and exceptionally powerful HTTP client. It's a premium product renowned for its native macOS experience, attention to detail, and advanced feature set tailored for Mac users.
Key Strengths:
- True Native macOS App: Excellent performance, system integrations (e.g., Touch Bar), and adherence to macOS design principles.
- Stunning UI/UX: Widely praised for its polished and intuitive interface.

- Dynamic Values & Extensions: Powerful system for generating dynamic data (faker data, hashes, auth tokens) and extending functionality with JavaScript or other languages.

- Accurate Code Generation: Generates high-quality client code for numerous languages.

- Environments & Schema Support: Robust environment management and support for API description formats.

- Platforms: macOS
- Pricing: Free
- Things to Consider: Mac-only, which is a dealbreaker for cross-platform teams. Premium pricing might not suit everyone.
11. Nightingale REST Client: A Fluent Design Postman Alternative for Windows

Nightingale aims to provide Windows users with a modern, native-feeling API testing experience, leveraging Microsoft's Fluent Design System. It offers a solid range of features for individual developers and small teams.
Key Strengths:
- Windows Native Look & Feel: Designed with Fluent Design principles for a cohesive Windows experience.

- Workspaces & Collections: Standard organization features.
- Request History & Environment Variables: Essential for efficient testing.
- Mock Server : Built-in functionality to create mock APIs.

- Platforms: Windows (Microsoft Store)
- Pricing: Free
- Things to Consider: Windows-only.
12. Karate DSL: A Test Automation Framework as a Postman Alternative

Karate DSL is not a direct GUI client like Postman, but rather a powerful open-source test automation framework built on top of Cucumber. It's specifically designed for API test automation and uses a BDD-style syntax that's easy to read and write, even for non-programmers.
Key Strengths:
- Native JSON/XML Support: Manipulate and assert on payloads without complex code.
- UI Automation Integration: Can call UI automation scripts (e.g., Selenium, Playwright).
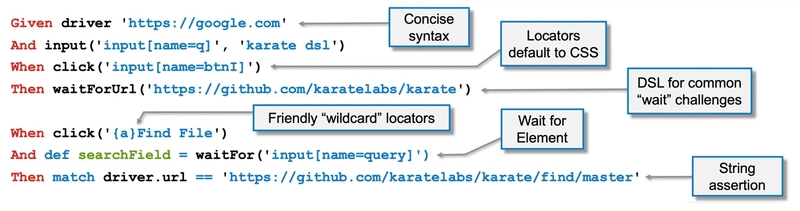
- Reusable Features & JavaScript Engine: Write reusable test logic and leverage JavaScript for complex scenarios.
- Platforms: Java-based (runs anywhere Java runs – Windows, macOS, Linux).
- Pricing: Open Source.
- Things to Consider: Requires some understanding of Java/Maven/Gradle for setup. Steeper learning curve than GUI tools for those unfamiliar with code-based testing or BDD. Not for interactive, exploratory API testing.
13. ReadyAPI (SmartBear): An Enterprise-Grade Postman Alternative

From SmartBear, the creators of SoapUI, ReadyAPI is a comprehensive, commercial API quality platform. It's designed for enterprises with complex API landscapes and rigorous testing requirements, covering functional, load, and security testing.
Key Strengths:
- End-to-End API Quality Platform: Integrates functional testing (ReadyAPI Test), performance testing (ReadyAPI Performance), and security testing (ReadyAPI Secure).

ing image](...)
- Strong Support for SOAP & Enterprise Protocols: Excels with WSDL, XSD, JMS, JDBC, and other enterprise standards, alongside REST and GraphQL.
- API Virtualization/Service Mocking: Create sophisticated mock services.

- Platforms: Windows, macOS, Linux
- Pricing: Commercial (requires a license, often per-user or per-module).
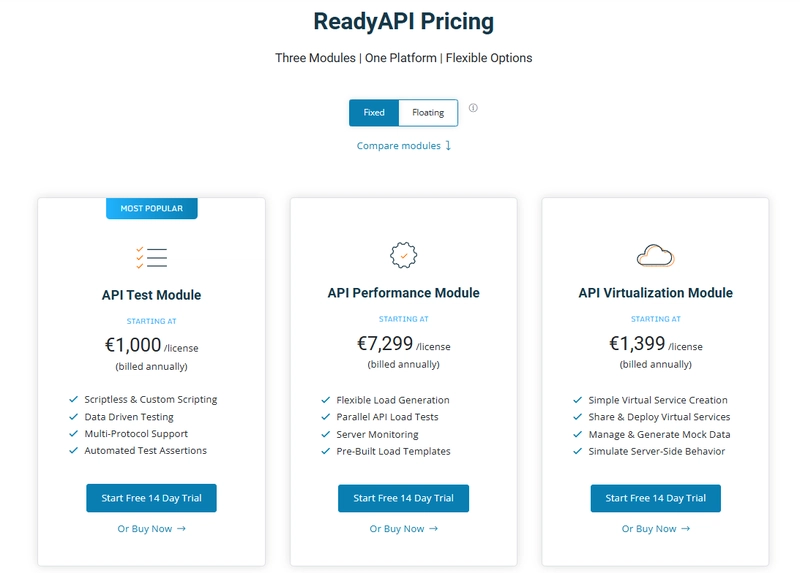
- Things to Consider: Significant cost. Can be overkill and overly complex for smaller teams or simpler API testing needs. The interface can feel dense due to the sheer number of features.
14. SoapUI: The Original Heavyweight Postman Alternative

While ReadyAPI is its commercial evolution, the open-source version of SoapUI remains a widely used and powerful tool, particularly for testing SOAP web services. It also has decent REST capabilities.
Key Strengths:
- Mature & Robust SOAP Testing: Gold standard for WSDL parsing, SOAP request generation, and WS-* standards (WS-Security, WS-Addressing).

- Groovy Scripting: Extensive scripting capabilities for complex test logic and assertions.
- Extensibility: Plugin architecture for adding custom functionality.
- Platforms: Windows, macOS, Linux (Java-based)
- Pricing: Open Source. A commercial "SoapUI Pro" version exists, which is essentially a component of ReadyAPI.
- Things to Consider: UI can feel dated and clunky compared to modern alternatives. Can be resource-intensive. Its REST testing features, while present, are not as slick or intuitive as tools built primarily for REST.
15. HTTPie: The CLI Postman Alternative for Humans

HTTPie is a command-line HTTP client designed for maximum ease of use and a human-friendly experience. Its intuitive syntax, JSON support, and beautiful terminal output make interacting with APIs from the command line a joy rather than a chore.
Key Strengths:
-
Simple & Expressive Syntax: Far more intuitive than cURL for common tasks.
http GET example.org name==John
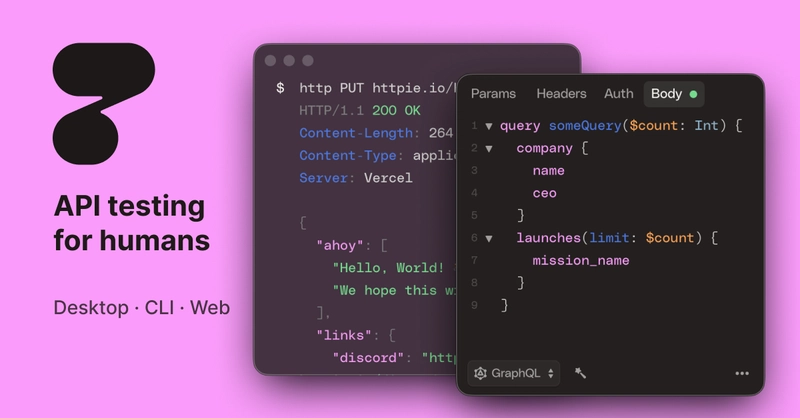
- Sensible Defaults: Often does what you mean without verbose flags.
- Built-in JSON Support: Automatically formats and colorizes JSON requests and responses.
- Forms & File Uploads: Simplified syntax for submitting forms and uploading files.


- Persistent Sessions: Easily reuse configurations like headers or auth across requests.
- Download Resumption & Proxies: Advanced networking features.
- Platforms: Windows, macOS, Linux (and anywhere Python runs)
- Pricing: Open Source (CLI). A new HTTPie for Desktop app is in development currently free beta, potential future paid features).
- Things to Consider: Primarily a CLI tool, so no GUI for managing complex collections in the same way as Postman (though the Desktop app aims to address this). Test scripting is done via shell scripting rather than an integrated JS engine.
Final Thoughts on Your Quest for Viable Postman Alternatives
Postman’s success has sparked a wave of innovation in the API space. From lightweight tools to full featured platforms, there’s something for everyone whether you're a solo developer, part of a large team, a CLI fan, or focused on API first workflows.
Exploring the right postman alternative can boost your productivity, improve collaboration, and elevate your API game.
Got a favorite Postman alternative I missed? Share it in the comments and help others find their perfect fit.


Top comments (30)
tbh postman got bulky so i get why folks are jumping ship - i've been switching between hoppscotch and bruno lately, kinda refreshing to go back to something fast and simple
Totally agree, Nevo! Postman paved the way, but it’s refreshing to work with tools like Hoppscotch and Bruno that keep things lightweight and fast. Appreciate you sharing your experience
Honestly, Postman has gotten pretty bloated, so I understand why people are moving away from it. I've been alternating between Hoppscotch and Bruno lately — it's refreshing to use tools that are fast and straightforward again. tiktok apk mod
That's a lot of information to digest. Thank you OP.
I have switched to testfully.io/. Previously used Postman and Insomnia.
That’s a solid switch, Testfully has been gaining traction lately. Thanks for sharing your stack.
Good call — switching to those tools makes sense. Testfully has also been picking up some momentum recently. Appreciate you sharing your setup. dine in restaurants near me
Bruno is my fav, but nice to know so many options. Good list!
Thanks! Bruno’s a solid choice. Glad you liked the list
Bruno for me, always!!!
Love the Bruno loyalty, It’s really made a name for itself by focusing on simplicity and performance.
Good information provided
Thanks, Nadeem! Glad you found it useful—always great to hear when the content hits the mark.
Thanks for all
You're welcome, Joel! Appreciate you taking the time to read and engage.
Good list. I like the simple, efficient tools instead of bulky postman.
Thanks, Kristen! I'm with you—there’s something really satisfying about using tools that just work without getting in the way.
Appreciate it, Kristen! I totally agree — there's something great about using tools that do their job without adding any friction. instaup apk
Awesome post, Emmanuel!
Thank you Audrey, hope you found the article informative.
Thank you for compiling the list, Emmanuel!
Thank you, Ananya! Really glad you found the list helpful